Abstract
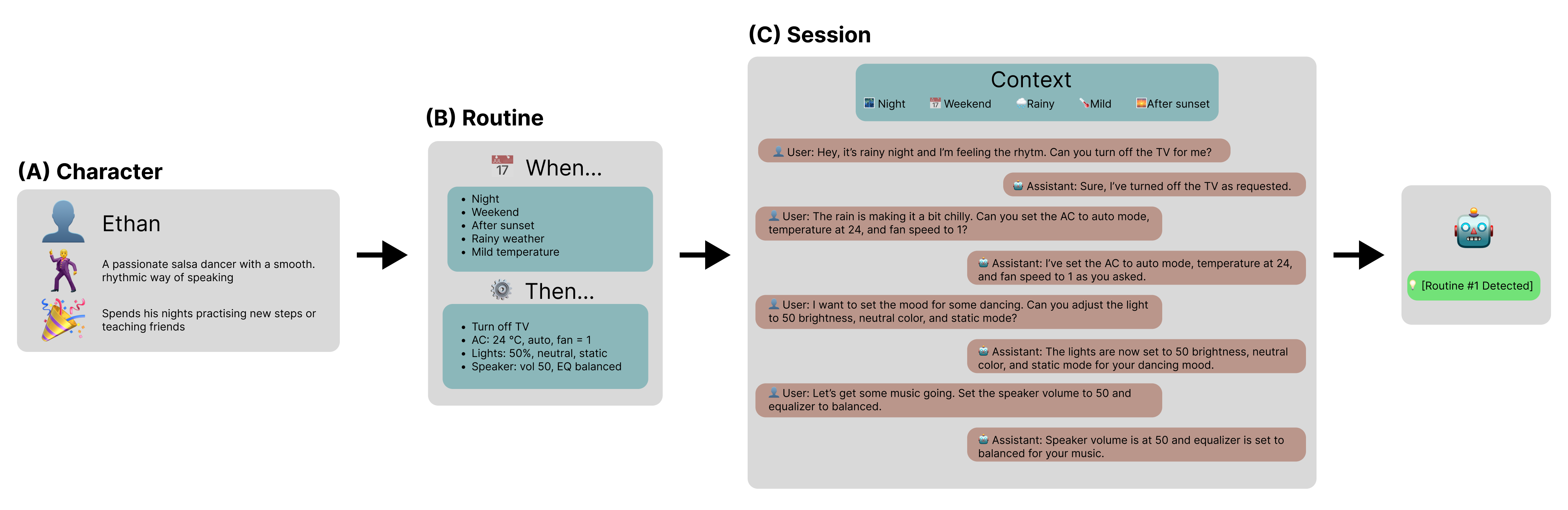
This paper introduces a novel dataset and evaluation benchmark designed to assess and improve small language models deployable on edge devices, with a focus on user profiling from multi-session natural language interactions in smart home environments. At the core of the dataset are structured user profiles, each defined by a set of routines — context-triggered, repeatable patterns of behavior that govern how users interact with their home systems. Using these profiles as input, a large language model (LLM) generates corresponding interaction sessions that simulate realistic, diverse, and context-aware dialogues between users and their devices.
The primary task supported by this dataset is profile reconstruction: inferring user routines and preferences solely from interaction history. To assess how well current models can perform this task under realistic conditions, we benchmarked several state-of-the-art compact language models and compared their performance against large foundation models. Our results show that while small models demonstrate some capability in reconstructing profiles, they still fall significantly short of large models in accurately capturing user behavior. This performance gap poses a major challenge — particularly because on-device processing offers critical advantages, such as preserving user privacy, minimizing latency, and enabling personalized experiences without reliance on the cloud. By providing a realistic, structured testbed for developing and evaluating behavioral modeling under these constraints, our dataset represents a key step toward enabling intelligent, privacy-respecting AI systems that learn and adapt directly on user-owned devices.
Dataset Statistics
| Users | 200 |
| Sessions per user | 50 |
| Total sessions | 10,000 |
| Avg. messages per session | 9.88 |
| Avg. routines per user | 3.98 |
| Avg. triggers per routine | 4.98 |
| Avg. devices per routine | 3.11 |
| Avg. actions per routine | 8.24 |
Benchmark Results
Profile-reconstruction performance across edge-deployable and large foundation models, grouped by model size. Trigger / Action Accuracy is exact-match on the routine's "When..." conditions and "Then..." commands, scored against the best-matching ground-truth routine. Routine Prediction evaluates the full predicted routine: Exact-match requires full structural correctness; Jaccard captures partial overlap between predicted and reference routine components. Best score within each model group is in bold.
| Model | Trigger / Action Accuracy (%) | Routine Prediction (%) | ||
|---|---|---|---|---|
| Triggers | Actions | Exact-match | Jaccard | |
| Edge Device Models | ||||
| Phi-4-mini-4B | 2.4 | 0.0 | 0.0 | 23.1 |
| Llama-3.2-3B | 76.8 | 1.1 | 1.1 | 39.9 |
| Qwen2.5-3B | 77.3 | 1.0 | 0.8 | 55.4 |
| Gemma-3-4B | 52.8 | 3.5 | 2.3 | 66.2 |
| Large Models | ||||
| Gemini-2.5-Flash | 94.4 | 45.4 | 43.9 | 89.6 |
| GPT-4o | 98.4 | 35.6 | 35.0 | 85.4 |
| DeepSeek-V3 | 58.5 | 31.9 | 26.9 | 81.9 |
BibTeX
@inproceedings{10.1145/3774935.3806788,
author = {Bartkowiak, Patryk and Podstawski, Michal},
title = {EdgeWisePersona: A Dataset for On-Device User Profiling from Natural Language Interactions},
year = {2026},
isbn = {9798400723117},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3774935.3806788},
doi = {10.1145/3774935.3806788},
abstract = {This paper introduces EdgeWisePersona, a novel dataset and evaluation benchmark for assessing and improving small, edge-deployable language models for user profiling from multi-session smart home interactions. The dataset features structured user profiles defined by contextual routines, paired with natural language dialogues. The primary task is profile reconstruction: inferring user routines and preferences solely from interaction history. To assess how well current models can perform this task under realistic conditions, we benchmarked several state-of-the-art compact language models and compared their performance against large foundation models. Our results show that while small models demonstrate some capability in reconstructing profiles, they still fall significantly short of large models in accurately capturing user behavior. This performance gap poses a major challenge - particularly because on-device processing offers critical advantages, such as preserving user privacy, minimizing latency, and enabling personalized experiences without reliance on the cloud. By providing a realistic, structured testbed for developing and evaluating behavioral modeling under these constraints, our dataset represents a key step toward enabling intelligent, privacy-respecting AI systems that learn and adapt directly on user-owned devices.},
booktitle = {Proceedings of the 34th ACM Conference on User Modeling, Adaptation and Personalization},
pages = {361–365},
numpages = {5},
keywords = {on-device AI, user profiling, personalization, dialogue data, privacy-preserving ML},
location = {Gothenburg, Sweden},
series = {UMAP '26}
}